Scalability fundamentals in Node.js
Notes from the book 'Node.js design patterns'
In its early days, Node.js was just a non-blocking web server written in C++ and JavaScript and was called web.js
Scalability: Capability of a system to grow and adapt to ever-changing conditions.
Its dependent on the growth of a bussiness.
has 6 faces. ‘The scale cube’
The capacity that a single thread can support is limited. If we want to use Node.js for high load apps, the only way is to scale it across multiple processes and machines.
Three dimensions of scalability
Load distribution:
splitting the load across several processes and machines.
There are many ways to achieve this, represented in the scale cube (Martin L. abbott, Michael T. Fisher)
-
X- axis: Cloning
Is the most intuitive evolution of a monolithic. It means cloning the same application N times and letting each instance handle 1/nth of the workload. (1000 reqs, 4 instances = 250reqs per instance)
-
Y-axis: Decomposing by service/funcionality:
Creating diferent, standalone apps, each with its own codebase (maybe also db, ui..) It’s the scaling dimension with the biggest repercussions (develpment and operational perspective)
-
Z-axis: Splitting by data partition:
The App is split. each instance is responsible for only a portion of the whole data. (horizontal/vertical partitioning). Its main purpose is overcoming problems related to handling large monolithic datasets. It should be considered only for complex, distributed architectures (Google scale). And after X and Y axes have been fully exploited.
X and Y are the most common in the Node.js ecosystem.
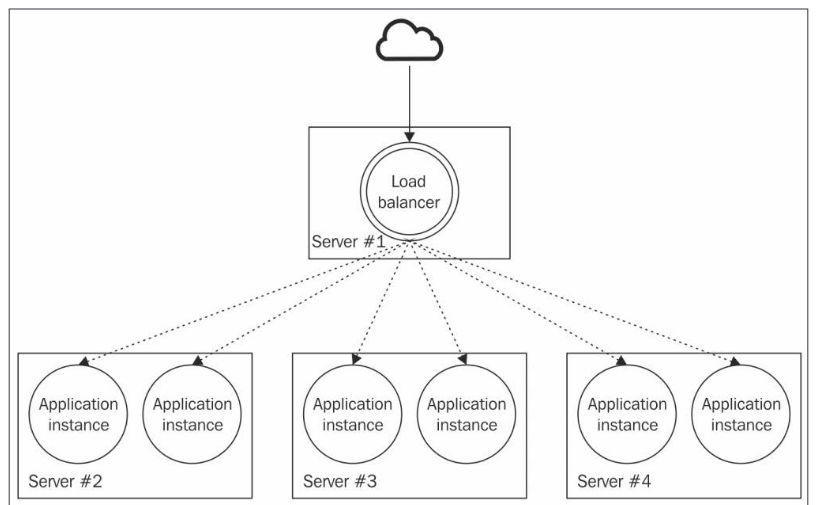
Cloning and load balancing
Nodejs applications are usually scaled sooner compared to traditional web servers that use multiple-threads. THis pushed the developer to take into account scalability from the early stages of an application, making sure the app does not rely on any resource that cannot be shared across mukltiple processes or machines.
The most basic mechanism for scaling is:
The cluster module
Part of the core Node.js libraries. Simplifies the forking of new instances of the same application and automatically distributes incoming connections across them.
The master process is responsible for spawning processes (workers, instances of the app) The load is spread across them.
You can spawn as many workers as number of CPUs available in the system. (Automatically done with PM2)
Notes:
The cluster module uses a round-robin load balancing algorithm (inside the master process). It distributes the load evenly across the available servers on a rotational basis. It also has some other behaviors to avoid overloading a given worker process.
When we call server.listen() in a worker process is delegated to the master process. This receives all incoming messages and distribute them to the pool of workers.
It's important to remember that each worker is a different Node.js process with its own event loop, memory space, and loaded modules.
We also have a communication channel available between the master and the workers. The worker processes can be accessed from the variable cluster.workers, so broadcasting a message to all of them would be as easy as running the following line of code:
Object.values(cluster.workers).forEach(worker => worker.send('Hello from the master'))
Resiliency and availability in cluster mode
By starting multiple instances of the same application, we are creating a redundant system. If one instance goes down, we still have other instances ready to serve requests.
We can listen for cluster.on('exit’) and create a new fork if the last one crashed. (PM2 handles this automatically)
Zero downtime restart
When we have to intentionally restart an application to update it, there is a small window in which the application restarts and is unable to serve requests.
With the cluster module, this is, again, a pretty easy task: the pattern involves restarting the workers one at a time.
Restarting workers
Stopping worker: 19389
Started 19407
Stopping worker: 19390
Started 19409PM2 handles this automatically with:
pm2 reload your-appYou can also see this process:
# Watch processes during reload
pm2 monit
# See logs during reload
pm2 logs
# Get reload status
pm2 show your-appStateful communications
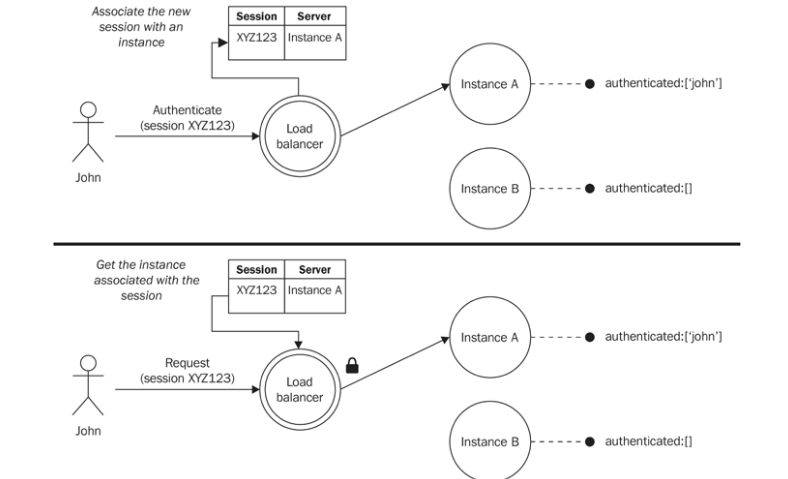
Different requests belonging to the same statefull session may potentially be handled by a different instance of the application. This is not a problem limited only to the cluster module, but, in general, it applies to any kind of stateless, load balancing algorithm.
- We can share state across all the instances with a shared datastore (db, Redis)
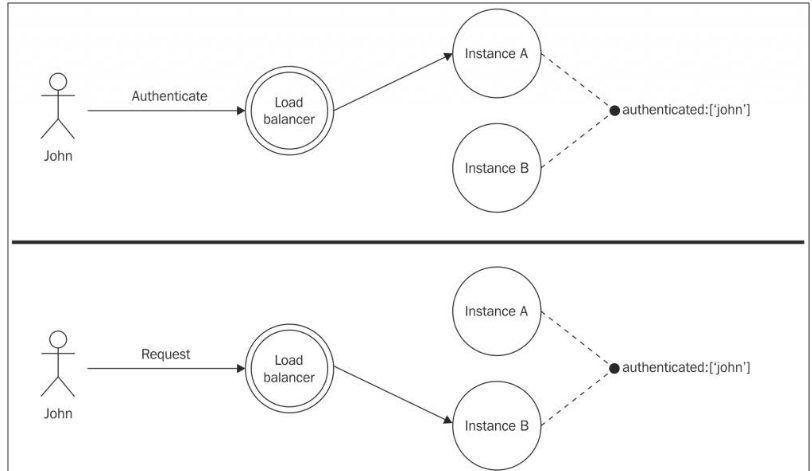
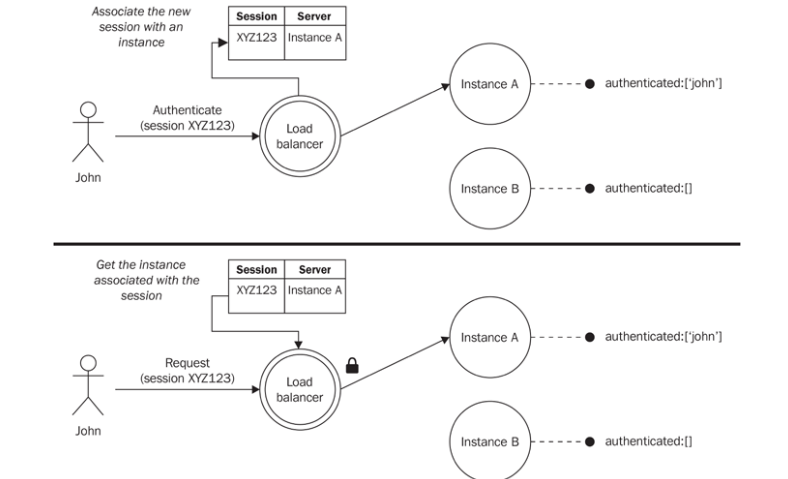
- Another options is sticky load balancing: is having the load balancer always routing all of the requests associated with a session to the same instance of the application.
Involves inspecting the session ID associated with the requests
This breaks the advantage of an instance that can eventually replace another one that stopped working.
-
Another alternative is to use the IP address of the client performing the request.
This technique has the advantage of not requiring the association to be remembered by the load balancer. (But is not that reliable for devices that change IP frequently)
The shared datastore is preferred, after building stateless communications. (Include all the necessary state in the request itself)
The cluster module is not the only option for scaling Node.js applications.
Scaling with a reverse proxy
The alternative is to start multiple standalone instances of the same application running on different ports or machines, and then use a reverse proxy (or gateway) to provide access to those instances, distributing the traffic across them.
Before:
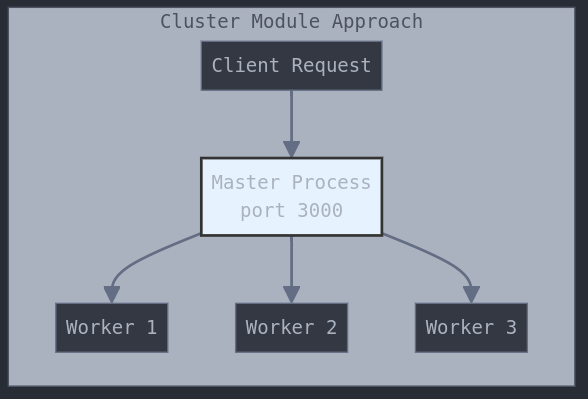
Now with reverse proxy approach:
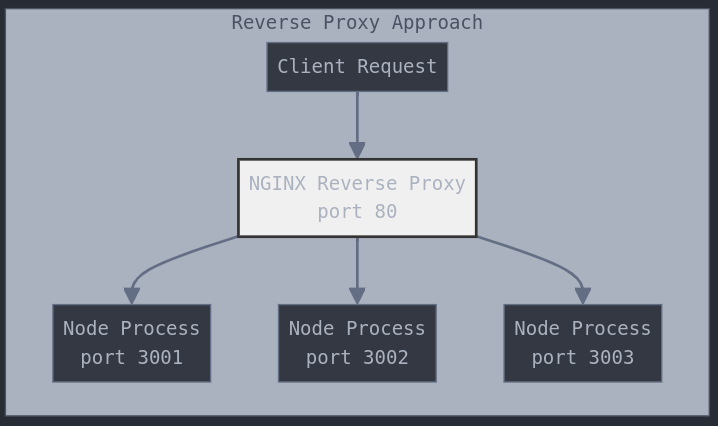
Or even better: Multi-process, multi-machine configuration with reverse-proxy as load balancer: